Manual to Magic: Building Automated Genomic Pipelines with AWS HealthOmics
Introduction
What if I told you we helped a genomics platform reduce their analysis delivery time by 90% and eliminate manual intervention entirely? That’s exactly what happened when we partnered with a client whose team was drowning in operational overhead—manually monitoring every workflow, babysitting EC2 instances, and running what felt like a 24/7 command center just to keep analyses moving.
The transformation came through AWS HealthOmics and event-driven architecture. Today, when their clients upload FASTQ files, the entire pipeline runs automatically—from data validation to workflow execution to results delivery. No human intervention required. No late-night alerts. No delayed results.
As genomics scientists, our client team were experts at designing analytical workflows but felt intimidated by cloud services like S3, Lambda, and EventBridge. Sound familiar? This post walks you through the complete serverless architecture we built together, explaining each AWS service in terms that make sense for genomics workflows. You’ll understand not just the technical implementation, but how these same patterns can transform your own genomic analysis pipelines from manual nightmares into automated solutions.
The Problem: Why Manual Genomic Workflows Don’t Scale
Our client came to us with a classic genomics platform problem. They were running Nextflow workflows on manually provisioned EC2 instances, and their operations team was constantly firefighting. Every time a client uploaded data, someone had to manually kick off the analysis, monitor resource usage, and troubleshoot when things inevitably went wrong.
The bottlenecks were everywhere. Workflow initiation required human intervention—literally someone checking for new uploads and starting jobs. Resource scaling was manual, meaning they either over-provisioned (wasting money) or under-provisioned (creating delays). When workflows failed, there was no automatic notification system, so issues often went undetected for hours.
Their clients were understandably frustrated. What should have been a streamlined analysis pipeline felt more like a black box with unpredictable delivery times. The genomics team spent more time managing infrastructure than actually improving their analytical workflows.
The breaking point came when they realized their operational overhead was growing faster than their client base. They needed a solution that could scale automatically, handle failures gracefully, and most importantly, run without constant human supervision. That’s when we introduced them to the power of serverless genomics on AWS.
Enter AWS HealthOmics: Your Nextflow Workflows in the Cloud
AWS HealthOmics was a game-changer for our client. Think of it as a managed service that takes your existing Nextflow workflows and runs them in the cloud without you worrying about the underlying infrastructure. No more provisioning EC2 instances, managing storage, or babysitting compute resources.
Here’s what makes HealthOmics special for genomics teams: it understands genomic data formats natively, automatically scales compute resources based on your workflow needs, and optimizes costs by using spot instances where appropriate. Your Nextflow scripts run exactly as they would locally, but now they’re backed by virtually unlimited cloud resources.
For our client, this meant their complex whole-genome sequencing pipelines could process multiple samples simultaneously without resource conflicts. HealthOmics automatically spun up the right instance types for each workflow step—memory-optimized instances for alignment, compute-optimized for variant calling—then shut them down when finished.
The best part? HealthOmics integrates seamlessly with other AWS services through events. When a workflow completes, it can automatically trigger downstream processes like result processing and client notifications. This event-driven capability became the foundation for the fully automated pipeline we built together.
The Magic of Event-Driven Architecture
Event-driven architecture might sound like technical jargon, but think of it like a well-orchestrated laboratory workflow. Instead of having someone manually check if each step is complete before starting the next one, each process automatically signals when it’s finished and triggers the next step in the chain.
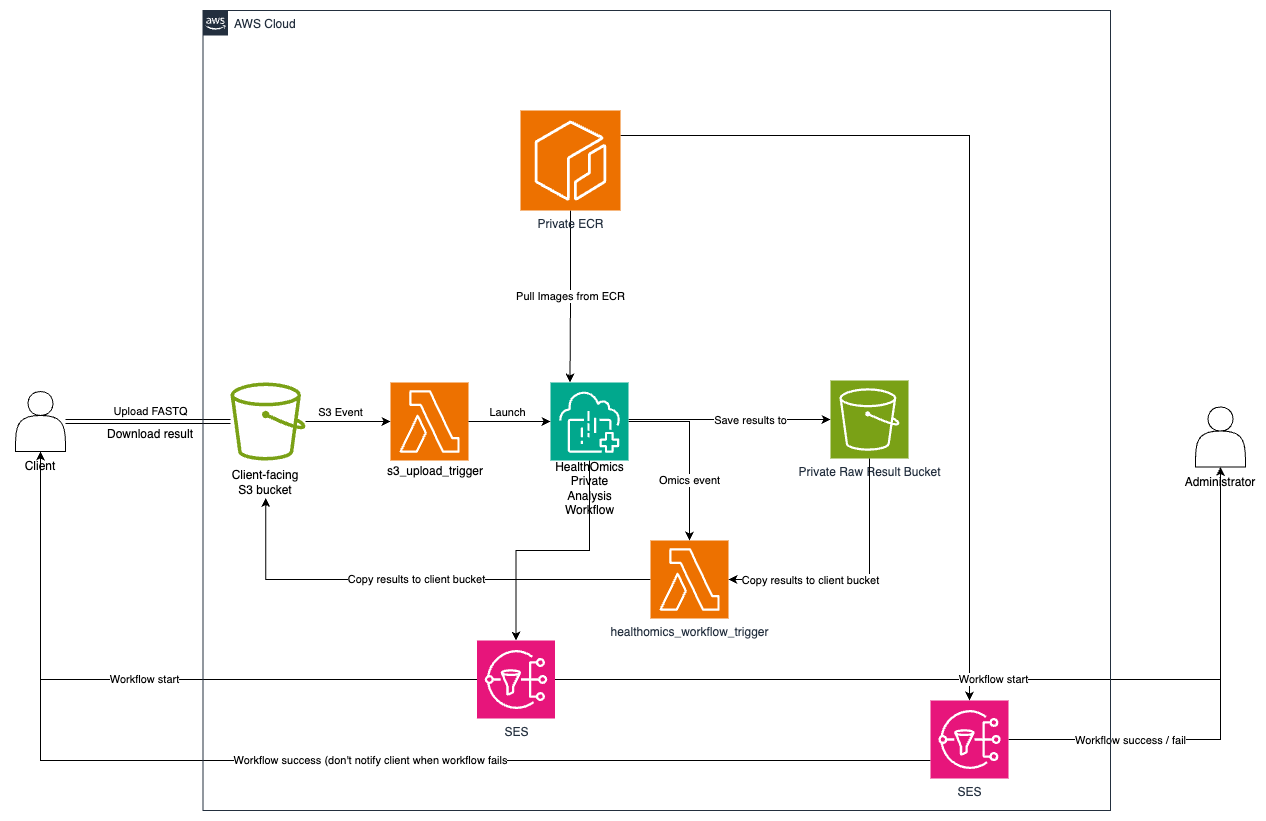
In traditional genomics pipelines, humans are the connective tissue—checking for uploaded files, starting workflows, monitoring progress, and delivering results. With event-driven architecture, these handoffs become automatic. When a client uploads data to S3, it creates an “event” that automatically triggers workflow validation and execution. When HealthOmics completes a workflow, it generates another event that automatically starts result processing and delivery.
For our client, this eliminated every manual touchpoint in their pipeline. File upload events trigger workflow initiation. Workflow completion events trigger result processing. Error events trigger notifications to the right people. It’s like having a tireless lab assistant who never misses a step and works 24/7.
The beauty is that each component operates independently but responds to events from other components. This makes the system incredibly resilient—if one part fails, it doesn’t bring down the entire pipeline. It also makes scaling effortless, since each component can handle more events without affecting the others.
Building Block 1: S3 as Your Data Foundation
Amazon S3 is essentially unlimited cloud storage that becomes the secure foundation for genomic data processing. Think of S3 “buckets” as dedicated project folders—each client gets their own isolated storage space, ensuring complete data separation and security.
1
2
3
4
client-genomics-bucket
└── project_1
├── sample001_R1.fastq.gz
└── sample001_R2.fastq.gz
The bucket structure follows genomics conventions with organized directories for raw FASTQ files and sample metadata. Security happens at multiple layers: each bucket is protected by access policies that restrict permissions to authorized users only, data is encrypted at rest, and all transfers happen within AWS’s secure network.
Here’s where the automation begins: when clients upload their genomic data files and metadata to the designated S3 location, these upload events automatically trigger the downstream processing pipeline. No manual notifications or intervention required—the simple act of uploading files becomes the signal that kicks off the entire automated workflow.
Building Block 2: Lambda Functions as Your Orchestrators
AWS Lambda functions are like having intelligent, always-available assistants that spring into action when needed. Unlike traditional servers that run continuously, Lambda functions are “serverless”—they only run when triggered by events, making them perfect for genomics workflows with sporadic processing needs.
We built two key Lambda functions for our client. The first acts as a workflow validator and initiator—when S3 upload events arrive, this function checks that all required files are present, retrieves client information, and starts the appropriate HealthOmics workflow with the right parameters. It also sends notifications to keep clients informed about workflow status.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
import boto3
# ...
def lambda_handler(event, context):
s3 = boto3.client("s3")
try:
buckey_name, key, directory = get_object_info(event)
if not validate_uploaded_files(bucket, directory):
subject = "Workflow start failed"
contents = [
("Detail", f"""
The workflow for s3 folder {bucket}/{directory} cannot be triggered successfully.
""")
]
send_email(client_email, subject, contents)
return
# If input data has passed validation, start HealthOmics workflow
response = start_healthomics(fastqs_uri, ids_uri, client_name, client_email, f"s3://{bucket}/{directory}/")
if response["status"] in ["'STOPPING','COMPLETED','DELETED','CANCELLED','FAILED'"]:
pass
# Send Workflow Fail Email
# Send Workflow Start Email
return
except Exception as e:
print(f"ERROR: {e}")
traceback.print_exc()
return
The second Lambda function handles results processing. When HealthOmics completes a workflow, this function automatically copies the relevant output files back to the client’s S3 bucket in an organized results directory. It filters out intermediate files that clients don’t need and ensures only the final reports and key outputs are delivered.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
import boto3
...
def lambda_handler(event, context):
try:
# If the workflow is "ING" state, do nothing
if "ING" in event["detail"]["status"]:
print(f"Workflow {event['detail']['runId']} is still running, do nothing")
return
if event["detail"]["status"] in FAIL_STATUS:
# Send an email to immunosis admin account about the failure
return
if event["detail"]["status"] == "COMPLETED":
# Copy all client facing results from private_bucket to client bucket
# Send an email to the client with the results
# Send an email to the administrator with the results
except Exception as e:
print(f"ERROR: {e}")
traceback.print_exc()
return
Both functions include comprehensive error handling—if required files are missing, clients get clear instructions on what to fix. If workflows fail, administrators are immediately notified with detailed logs. The beauty of Lambda is that these functions scale automatically with demand and only cost money when they’re actually running, making them incredibly cost-effective for genomics workloads.
Building Block 3: EventBridge for Status Monitoring
Amazon EventBridge acts as the central nervous system that connects all your AWS services together. Think of it as an intelligent message router that listens for important events and automatically notifies the right components when something happens.
In our genomics pipeline, EventBridge monitors HealthOmics workflow status changes. When a workflow transitions from “running” to “completed” or “failed,” HealthOmics automatically sends these status updates to EventBridge. Instead of having someone manually check workflow progress, EventBridge instantly routes these events to the appropriate Lambda function for processing.
This “publish-subscribe” pattern means components don’t need to constantly check on each other—they simply announce when something important happens and let other components respond accordingly. For our client, this eliminated the need for manual monitoring dashboards and reduced notification delays from hours to seconds.
EventBridge also provides built-in retry logic and error handling. If a downstream service is temporarily unavailable, EventBridge will automatically retry delivering the event, ensuring no workflow completions get missed. This reliability was crucial for maintaining client trust in the automated system.
The result is a self-managing pipeline where each component knows exactly when to act, creating the seamless automation that transformed our client’s operations.
The Complete Data Flow: From Upload to Results
Let’s trace through exactly what happens when a client uploads their genomic data, because understanding this flow shows the power of event-driven automation.
Phase 1: Upload and Initiation When clients upload their FASTQ files and metadata to their S3 bucket, the upload event immediately triggers the first Lambda function. This function validates that all required files are present, extracts client information from the bucket configuration, and launches the appropriate HealthOmics workflow. Clients receive an email confirmation with their workflow ID within seconds of uploading.
Phase 2: Processing and Delivery While HealthOmics processes the genomic data using the client’s Nextflow pipeline, EventBridge continuously monitors the workflow status. The moment HealthOmics signals completion, EventBridge triggers the results-processing Lambda function. This function automatically copies the final analysis reports to the client’s results directory and sends a completion notification with download instructions.
For failed workflows, administrators receive immediate alerts with detailed error information, while clients get helpful guidance on resolving any data issues.
Timeline: What used to take hours of manual coordination now happens in minutes. Upload to workflow initiation: under 1 minute. Workflow completion to results delivery: under 2 minutes. The only variable is the actual analysis time, which HealthOmics optimizes automatically.
Security and Data Isolation: Keeping Client Data Safe
Security in genomics isn’t optional—it’s fundamental. Our architecture ensures each client’s data remains completely isolated while maintaining the convenience of automated processing.
The foundation is per-client S3 buckets with strict access controls. Each bucket operates like a private vault—clients can only access their own data, and IAM policies enforce these boundaries automatically. Even our Lambda functions receive only the minimum permissions needed for their specific tasks, following the principle of least privilege.
Data encryption happens at every layer. Files are encrypted at rest in S3, encrypted in transit during transfers, and processed securely within HealthOmics workflows. All data movement occurs within AWS’s private network—nothing touches the public internet unnecessarily.
Client authentication uses AWS access keys with tightly scoped permissions. Clients can upload data and download results from their bucket, but they can’t accidentally access system components or other clients’ data. This approach scales beautifully—adding new clients doesn’t require complex security reconfigurations.
The serverless architecture actually enhances security compared to traditional approaches. There are no long-running servers to patch or maintain, no persistent connections that could be compromised, and every component logs its activities for complete audit trails. When combined with AWS’s enterprise-grade security infrastructure, this creates a platform that’s more secure than most on-premises solutions.
Results That Matter: The 90% Improvement Story
The transformation was dramatic and measurable. Before automation, our client’s typical workflow took 2-3 days from data upload to results delivery—not because the analysis was slow, but because of all the manual handoffs. Someone had to notice the upload, validate files, start the workflow, monitor progress, process results, and notify clients. Each step introduced delays and potential errors.
After implementing the serverless pipeline, that same process now takes 3-4 hours total. Upload to workflow initiation happens in under a minute. Results processing and delivery complete within minutes of workflow completion. The only time that matters now is the actual genomic analysis, which HealthOmics optimizes automatically.
Client satisfaction improved immediately. Instead of wondering when their results would be ready, clients receive clear notifications at every stage. They can focus on interpreting results rather than chasing status updates. One client told us, “It feels like magic—I upload files in the morning and have results by lunch.”
The operational impact was equally impressive. Our client’s platform team went from constantly monitoring workflows to focusing on improving analytical methods. Infrastructure costs dropped 40% due to automatic scaling and elimination of idle resources. Most importantly, they can now onboard new clients without increasing operational overhead—the automated system scales seamlessly.
The architecture handles failure gracefully too, with immediate notifications and clear error messages that help clients resolve issues quickly.
Conclusion
What started as a manual nightmare became an automated success story. Our client went from spending most of their time managing infrastructure to focusing entirely on advancing their genomic analysis capabilities. The 90% reduction in delivery time wasn’t just about speed—it was about transforming their entire business model from reactive operations to proactive innovation.
The combination of AWS HealthOmics and event-driven architecture proves that genomics platforms don’t have to choose between scientific rigor and operational efficiency. With the right cloud architecture, you can have both: robust, scalable analysis pipelines that run themselves while maintaining the highest standards for data security and quality.
For genomics scientists hesitant about cloud adoption, remember that these AWS services are tools designed to amplify your existing expertise, not replace it. Your Nextflow workflows remain unchanged—they just run better, faster, and more reliably in the cloud.
Start with one workflow, learn the patterns, and build confidence. The genomics industry is moving toward automated, cloud-native platforms, and the teams that embrace this transition early will have a significant competitive advantage. Your clients are already expecting faster, more reliable results—now you have the blueprint to deliver them.